TL; DR
- Начиналось как внутренний research-инструмент, выросло в продукт: врач в Европе ежедневно готовит документы через облачную LLM, не отдавая ей ни одного персонального данного. Агентская часть той же истории — в кейсе про агента.
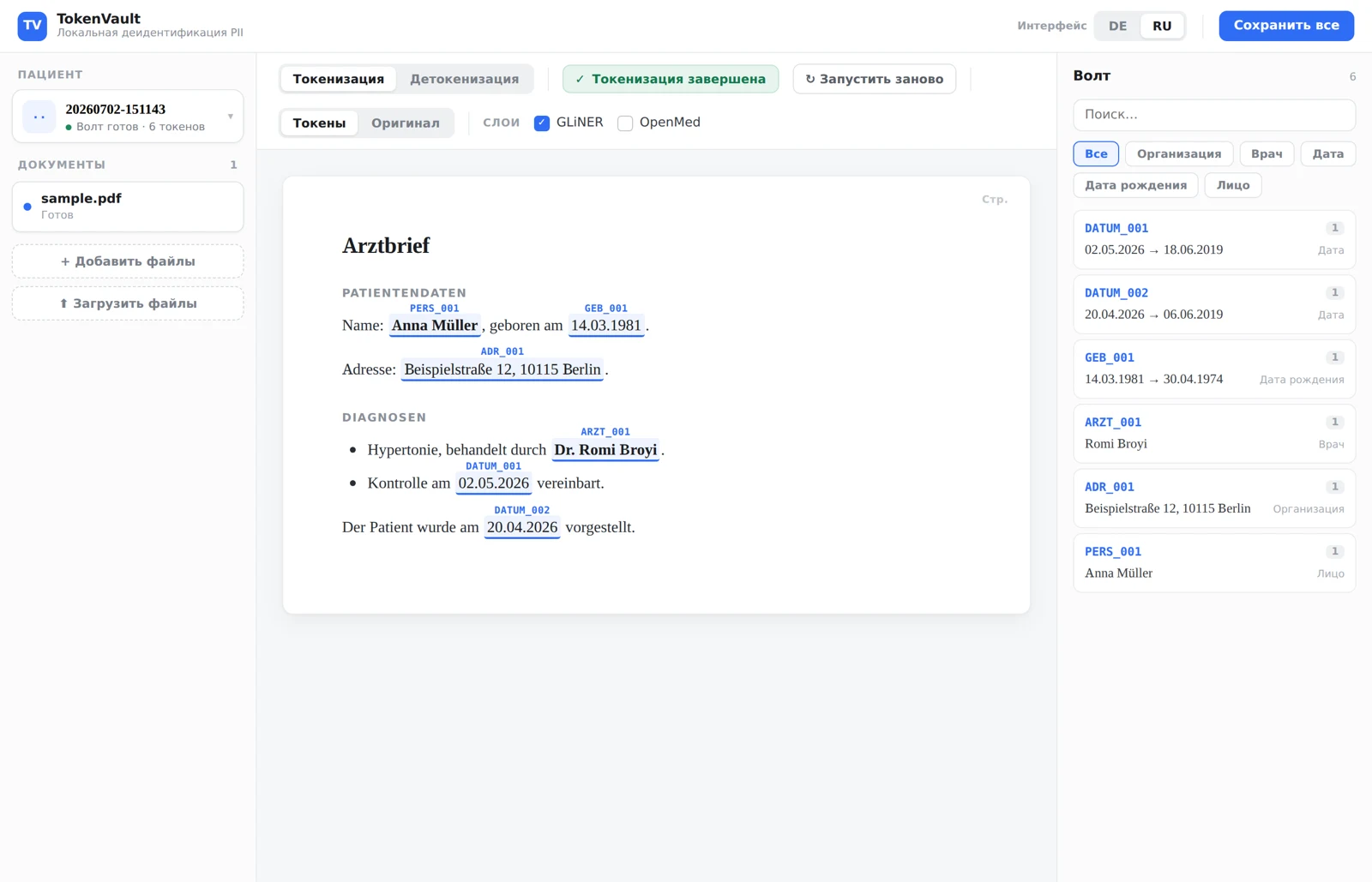
- Обезличивание обратимо: PDF → структурный Markdown → токенизация → LLM → восстановление → готовый PDF. Имена и адреса уходят кодами (
PERS_001), даты — сдвигаются с точным сохранением возраста и интервалов, а на обратном пути всё восстанавливается байт-в-байт. - Распознавание — ансамбль из трёх слоёв, и вклад каждого измерен на реальных документах, а не принят на веру: лишний слой после замера выключен.
- Обезличивание одного документа: вместо часа руками — около 5 минут вместе с проверкой.
Контекст
Клиент — врач с частной практикой в Европе, готовит объёмные медицинские заключения. LLM сильно ускоряет работу с текстом, но есть жёсткое ограничение: персональные данные пациентов нельзя отдавать в облачные модели — врачебная тайна защищена уголовным правом, а не только регламентами.
Задача: врач работает с настоящим документом, облачная модель — с обезличенным двойником, и после работы модели данные возвращаются на место. Всё — локально, на компьютере врача.
Проблема
Первый прототип «LLM сама обезличивает» провалился предсказуемо: модель оставляла имена «по контексту», плейсхолдеры разъезжались, повторный прогон давал другой результат. Для медицины это стоп-фактор — я про это писал в ранней версии этого кейса.
Но и «просто заменить имена кодами» недостаточно. Настоящие грабли глубже:
- Даты нельзя токенизировать. Модель, получившая
DATE_003вместо даты рождения, не может рассуждать о возрасте и давности болезни — а это половина клинического смысла. - PDF превращается в кашу. Наивное извлечение текста убивает заголовки, списки и структуру — врач получает на ревью «стену текста», а на выходе — документ без форматирования.
- LLM ошибается в токенах. Модель может опечататься в коде (
PERS_01вместоPERS_001) — и битый код молча уедет в финальный документ.
Подход
Принцип тот же, что в прототипе — модель там, где нужна, код там, где можно без неё — но реализация взрослая:
- Ансамбль распознавания. Многоязычная NER-модель находит имена и адреса по смыслу, детерминированные правила ловят жёсткие форматы (номера дел, IBAN, телефоны), память запоминает подтверждённые врачом решения. Каждый слой оставляет след: видно, кто нашёл каждую сущность.
- Замер вместо веры. На реальных (анонимизированных) документах измерил вклад каждого слоя: основная модель покрывает 95% находок, а второй нейрослой давал ~1% уникального — и тот шум. Выключил его по умолчанию: минус четверть времени прогона, ноль потерь. Ансамбль — это то, что доказало пользу замером, а не то, что накидали «на всякий случай».
- Обратимость через хранилище токенов. Каждой сущности — стабильный код, таблица замен живёт только на компьютере врача. Даты не кодируются, а сдвигаются на единый случайный сдвиг: возраст пациента и интервалы между визитами сохраняются с точностью до дня, но настоящих дат модель не видит.
- Структура выживает весь круг. PDF конвертируется в структурный Markdown (заголовки, жирный, списки) — врач проверяет читаемый документ, модель получает читаемый документ, и финальный PDF собирается с форматированием.
- Защита от ошибок модели. Если LLM исковеркала или выдумала токен — при восстановлении врач видит красное предупреждение со списком битых кодов, а не молча испорченный документ.
- Ревью как рабочее место. Веб-интерфейс: подсветка находок в документе, карточка каждого токена (сменить тип, убрать ложное срабатывание, добавить в словарь), привязка к пациенту, журнал раскрытий.
Результат
- Обезличивание документа: около 5 минут вместе с ревью — против часа руками.
- Круг «PDF → обезличить → LLM → восстановить → PDF» проверен end-to-end: восстановление байт-в-байт, утечек на пробах — ноль.
- Врач ставит обновления сам, двумя кликами; 330+ автотестов держат каждое изменение.
- Инструмент стал частью ежедневного потока: в связке с агентом врач формулирует задачу один раз — и работает с готовым результатом.
Что бы сделал иначе
Мерил бы вклад каждой модели с первого дня. Ансамбль «на всякий случай» полгода тратил четверть времени каждого прогона на слой, который — как показал первый же честный замер — не приносил почти ничего. Замер занял вечер; вера в «больше моделей = надёжнее» держалась месяцами.